
Depuis des années, je développe des applications web basées sur les frameworks ASP.Net. Et plus récemment avec le framework ASP.Net Core.
Fort de cette expérience, je vais vous présenter, dans une série d’articles, des pistes d’optimisation de performances des applications web .Net.
Amélioration des applications, avec quels moyens ?
Ces frameworks ont nettement évolué depuis la version 2.0. Il est désormais assez simple de démarrer un projet à partir de l’IDE Visual Studio pour répondre à une demande client.
Les applications web sont souvent liées à une ou plusieurs bases de données (directement, ou indirectement via des APIs). Les versions récentes de SQL Server Management Studio permettent aux développeurs de « tuner » un minimum ces bases afin d’obtenir des requêtes avec un temps de réponse acceptable.
Construire une application web avec un minimum de rendu graphique est donc à la portée de toute équipe de développement. Mais, il est essentiel que les performances de cette application restent optimales au fil des versions déployées. En effet, plus une application évolue, plus les lenteurs de chargement des écrans apparaissent. Optimiser les performances d’une application à un certain stade de maturité du projet relève très souvent de la gageure !
Il est donc important de veiller constamment aux performances de l’application dès sa conception. Puis, tout au long de sa réalisation.
Dans cette série d’articles, je vais évoquer quelques astuces utilisées durant mes expériences pour fluidifier la navigation des applications.
La base de données
L’optimisation d’une application se fait dès le début du projet en commençant par la base de données.
Le design d’une base relationnelle suivant de bonnes pratiques est crucial car c’est par là que tout commence. Avant de se lancer dans la conception du schéma de la base, il est primordial de cataloguer les données que l’on va utiliser en sachant que ce catalogue sera constamment amené à évoluer.
Le jeu consiste à pouvoir identifier les tables de référence et les tables qui vont contenir les données. Puis à imaginer les appels qui, par l’intermédiaire de procédures stockées ou bien à partir d’un ORM, vont requêter l’ensemble de ces tables. Le tout, en cherchant à réduire le plus possible les jointures faites entre ces tables.
L’optimisation côté SQL
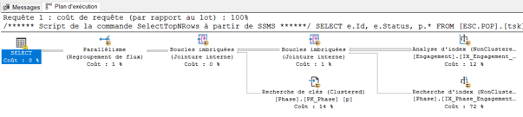
Analyse du traitement des requêtes avec SQL Server Management Studio
Il existe des outils simples que le développeur utilise tous les jours, comme le SQL Server Management Studio. Cet outil puissant fournit certaines fonctionnalités très utiles mais dont beaucoup ignorent l’existence, comme le plan d’exécution par exemple.
Cette fonctionnalité permet d’analyser la manière dont le moteur SQL va traiter une requête pour identifier ses points faibles. Cela aidera le développeur à réécrire la requête pour améliorer les temps de réponse, redéfinir les clés, les contraintes ou encore les index des tables.
SQL Server Profiler, un outil de traçage performant
SQL Server Profiler est un autre outil que j’utilise très souvent pour réécrire les appels faits à la base de données. Je l’utilise car les applications que je conçois sont pratiquement toujours basées sur l’utilisation d’un ORM comme Entity Framework ou NHibernate. Et qui dit ORM, dit requête générée. C’est donc du code SQL dont on n’a pas forcément la maîtrise et qui très souvent produit un nombre important de jointures.
Cette interface permet de tracer toutes les requêtes SQL transitant par la base. Cela permet d’ajuster les projections, de réduire le nombre de jointures des requêtes SELECT et d’améliorer les temps de réponse.

Mais ces outils permettent seulement de diagnostiquer les problèmes de lenteurs, pas de les résoudre : il faut un minimum de bon sens lorsque l’on conçoit une application.
Prenons l’exemple des tables de référence : ces tables contiennent des informations quasi statiques, nécessaires au paramétrage du fonctionnement de l’application ou à l’enrichissement des données. Or, une table contenant des codes postaux n’aura pas la même cardinalité qu’une table contenant des civilités. Cette dernière ne contenant que 2 enregistrements (M, Mme), il n’est pas nécessaire de créer une table qui générera forcément des jointures : il est plutôt préférable de créer une énumération côté code. Pourquoi ? Car cette énumération n’évoluera jamais.
La pagination côté serveur
Enfin, il y a un dernier sujet que j’aimerais aborder dans cet article et qui concerne les listes paginées. Des bibliothèques de composants, comme Telerik, permettent de faire ceci en 3 clics. C’est un jeu d’enfant !
Mais c’est aussi un piège : la pagination se fait nativement côté client et non côté serveur. Cela peut passer lorsque le nombre d’enregistrements à paginer est faible. En revanche, cela devient un vrai problème lorsque ce nombre devient important.
La bonne pratique consiste à mettre en place une technique de pagination côté serveur, et ce, dès le début du projet, sachant que ce genre de composant est en général très utilisé.
Il y a bien sûr bien d’autres astuces qui permettent d’améliorer les temps de réponse des appels faits à la base comme la mise en cache, le paramétrage des ORMs, etc.. Mais c’est déjà un début. 🙂
Pour les autres astuces, je les aborderai sur les prochains articles de cette série ! Le prochain est consacré à l’optimisation des performances des applications côté code.

